


Introduction: A Brief History
Although very few people realized it at the time, 2017 was the beginning of the current AI explosion. That year, Google researchers published the now-famous paper Attention is All You Need, which introduced the concept of the transformer, a method by which text can be tokenized and reconfigured in a more usable form.
The transformer architecture was revolutionary, ushering in the era of large-language models (LLMs). Within just one year of Google’s paper, OpenAI released GPT-1 (June 2018), followed shortly thereafter by GPT-2 (February 2019) and GPT-3 (May 2020). Suddenly, it seemed like you could throw exponential amounts of money, data, and compute at a model, and it would achieve exponentially better results.
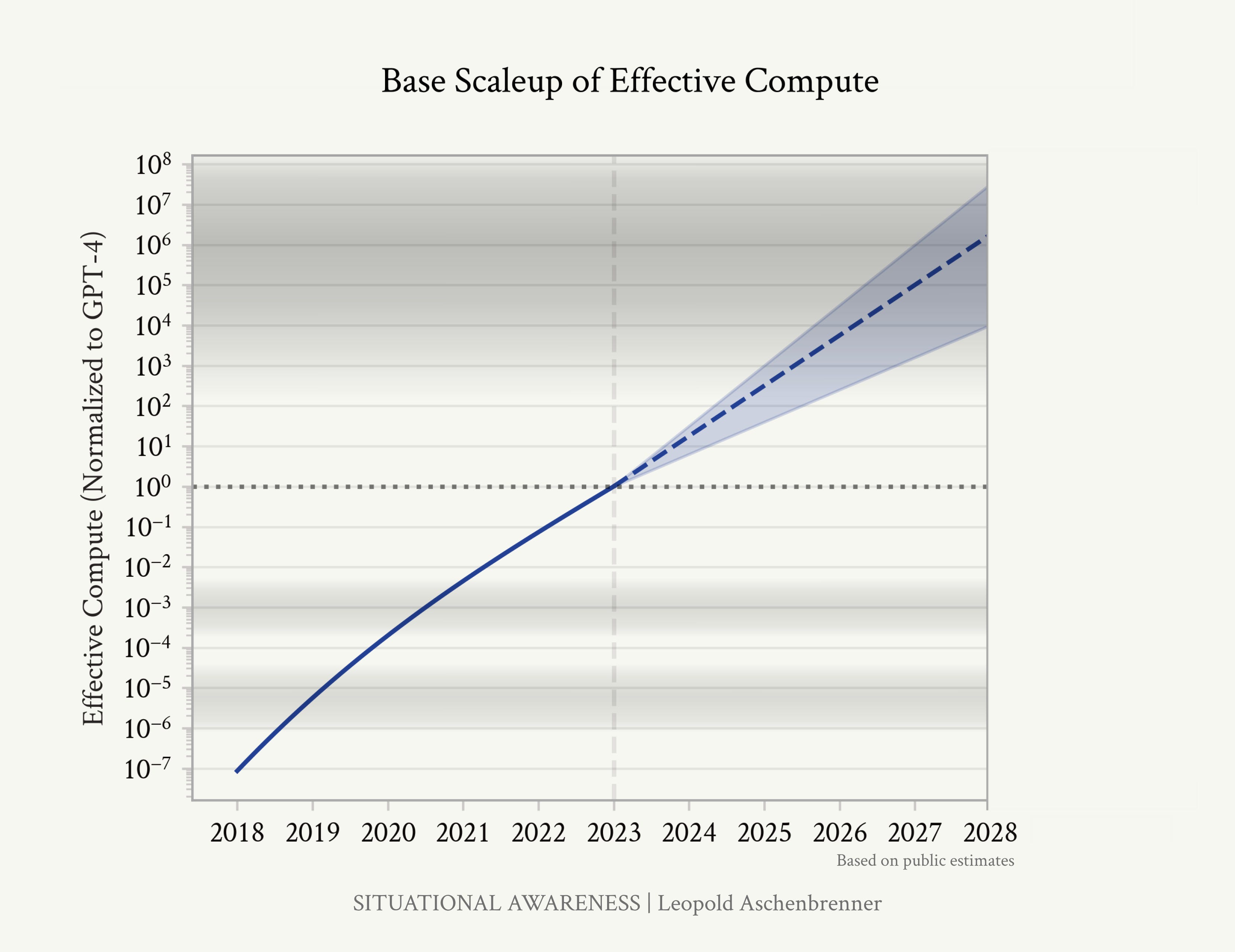
A graph of effective compute in leading AI models from 2018 - 2023, with projected numbers from 2024 - 2028. Note the logarithmic scale. (Modified from source.)

“Scale is all you need” has become a common meme within the AI community — meaning, there’s nothing that AI won’t be able to achieve once it gets enough compute and data.
Around the same time (2019), researchers developed the process of reinforcement learning with human feedback (RLHF). This is a method of finetuning which uses humans to grade various LLM outputs, rewarding those outputs which meet the developers’ criteria and punishing those which do not. In other words, LLMs can synthesize the text from their training data, while RLHF sorts through the results and outputs the ones you want. Together, LLMs augmented by RLHF became the foundation of modern chatbot services like ChatGPT (released November 2022).1 Not to be outdone, a flurry of other developers have come out with their own models since 2022 — Meta’s Llama, Google’s Gemini, Anthropic’s Claude, and now Elon Musk with Grok.
Yet, something curious has happened over the last 18 months — or rather, hasn’t happened. Ever since the release of GPT-4 in March 2023, there has not been any significant increase in AI capabilities. (Claude 3.5 Sonnet is arguably better than GPT-4, but not by much.) In spite of hundreds of billions of dollars in investment money and the dedicated work of the world’s top machine learning experts, no AI company has yet developed a model that can write better than a smart high schooler. Lofty promises were made about AIs which could generate trillions in profits or automate large portions of the workforce, but neither of those promises have yet panned out. Rumors that “AGI has been achieved internally” similarly turned out to be false.2 Progress, it seems, has stagnated.
(Just to be clear, it’s not as if the leading AI models have made no significant progress over the last 18 months. They have become far more efficient in their use of compute and energy, which has made them much less expensive. The best example of this is the July 2024 release of GPT-4o mini, which costs an order of magnitude less per token than GPT-4, while retaining most of GPT-4’s capabilities. So even if AI has not become 10 times better since 2023, it has become 10 times cheaper.)
Why is the rate of capabilities progress seemingly slower today than it was from 2017 - early 2023? Is it just a temporary delay? Or have we hit a ceiling, where we can make little further progress using current methods? In this post, I will try to give the best arguments for both sides, to help you make sense of the rhetoric and have a clearer picture of the current state of AI development.
Arguments For There Being a Ceiling
A lot of models seem stuck at the GPT-4 level.
At least 5 AI labs have managed to create GPT-4-level models over the last 18 months (GPT-4 itself, Llama 3.1, Claude 3.5 Sonnet, Gemini Ultra, and Grok-2), but so far none of them have gone above that. The fact that so many different developers have gotten stuck at approximately the same point suggests that it is relatively easy to build a new GPT-4-level model (assuming you have billions of dollars to throw at compute and research), but rising to GPT-5 requires something greater. What is that “something greater”? Maybe it just means a lot more scale, or maybe it means we need an entirely new approach from what we’ve been doing so far.
In either case, the more companies that get stuck right before reaching GPT-5, the more evidence we have that GPT-5 may be impossible to achieve (at least in the near-term).
Even one bottleneck could stop us from scaling.
“Artificial intelligence” isn’t just one thing. It’s actually a combination of factors that allow advanced models to function. Researchers sometimes talk about the “AI Triad” consisting of algorithms, data, and compute, all of which are necessary for the models we use today. The years 2017 - 2023 were so unique because all three factors, mostly by coincidence, advanced at once. But some experts have warned that if any of those factors faces a bottleneck, then our current wave of exponential growth could slow to a crawl.
There are multiple plausible ways that such a bottleneck could happen. Take compute, for example. For many years, compute famously advanced according to Moore’s Law, which stated that the number of components per integrated circuit would double every two years. But somewhere around 2015, Moore’s Law died. Compute efficiency has still increased, but not nearly at the same exponential rate it once did. We may soon reach the upper limit of how many components we can possibly squeeze per nanometer.
Data is another bottleneck. AI companies have already scraped the entire internet for data — practically every chat board, blog, social media post, and book ever uploaded online is baked into the current models. There is essentially no more data left to mine. (And, much of the data we currently have is becoming unusable due to data poisoning and copyright issues.) Unless we find an alien civilization whose data we can harvest, then we have again reached an upper limit.
Human intelligence is about responding to novel situations, not stochastic parroting. It is not clear that any amount of scaling could match human creativity.
Fundamentally, what is the difference between human and artificial intelligence?
Humans learn a set of first principles, and then generalize. These principles are things like “What An Object Is”, “How Language Works”, and “How Light Looks”. Humans learn these principles extremely early — practically the first thing a baby does is absorb the speech of the people around it and learn to repeat that speech. You don’t need to read every piece of text in the English language to understand how English works; as long as you know enough vocabulary and basic grammar rules, you can participate in an English conversation. You don’t need to see a list of 10,000 circles to understand what a circle is; as soon as you see one circle, you can pretty easily guess what the other 9,999 will look like. This ability to generalize allows humans to solve new problems and respond to new situations that we haven’t seen before.
Artificial intelligence, by contrast, is based on stochastic parroting. That is, the model takes in immense amounts of data, analyzes the patterns within that data, and then repeats those patterns with a bit of randomness added. If you ask ChatGPT to write a holiday greeting message, it will look through its archive of holiday greeting messages and produce a composite of that. If you ask ChatGPT to generate an image of a circle, it will look through its archive of circle images and produce a composite of them. This method certainly has some benefits over human cognition. AI can work significantly faster than humans, hold significantly more memory, and speak in a variety of styles and about a variety of topics that no single human could. However, since AI can only respond based on its training data, it will utterly fail when confronting novel situations, which by definition have no previous training data.
Perhaps the greatest example of this in practice is the ARC Prize. I plan to say much more about ARC in a future post, but the basic description is this: There is a series of pixel puzzles based on basic shape transformations. Each puzzle has a series of example inputs and outputs with a pattern. To solve the puzzle, you must correctly identify the pattern, and apply it to a test input to predict the final answer.
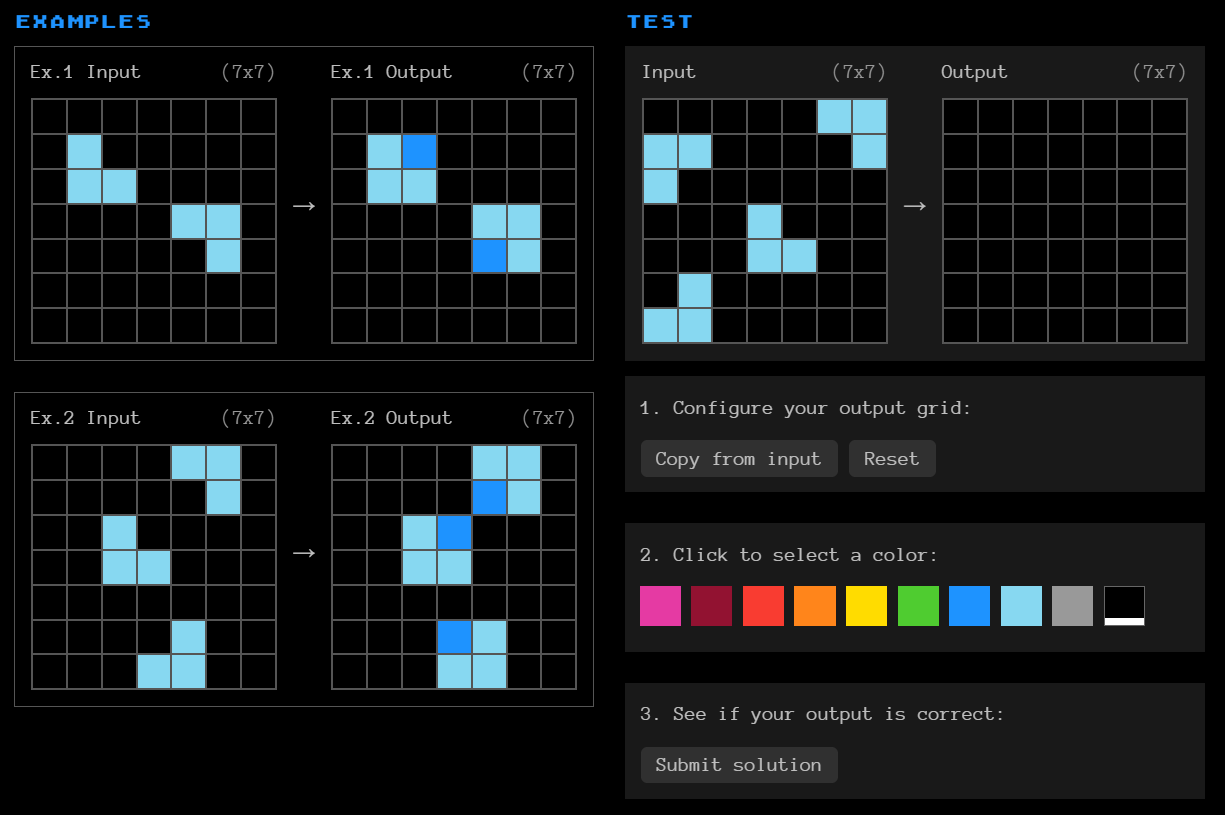
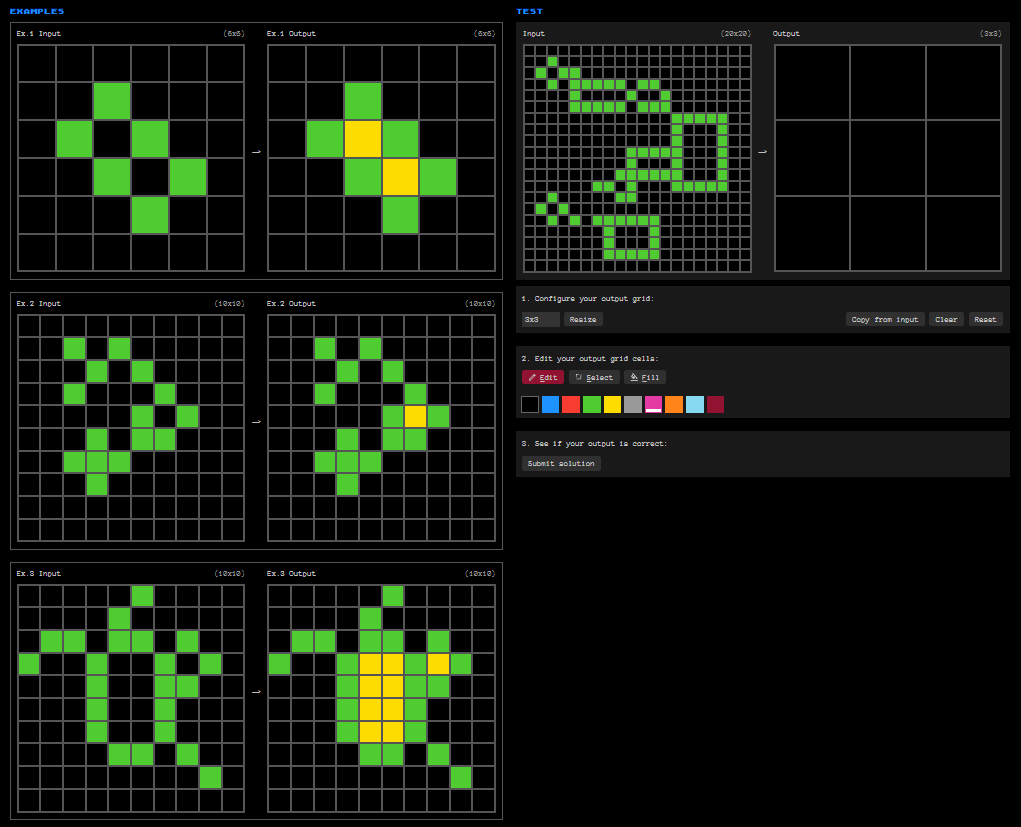
Two examples of puzzles from the ARC Prize. To view more, or to test your answers, visit https://arcprize.org/play.
Humans, who are great at recognizing patterns from new information, can solve these puzzles fairly easily — smart humans have been able to solve them with roughly 85% accuracy. AI, by contrast, struggles. So far, the leading AI solver has been able to correctly solve only 46% of the puzzles within the ARC Prize testing set. (And it’s not for lack of trying. The ARC Prize was first created in 2019, and there have been multiple rounds of competition where top researchers compete to design the greatest AI solver. There is currently $1,000,000 in prize money for whoever can get closer to a solution.) The fact that humans remain far superior to AI at solving these puzzles suggests that the human way of learning is extremely difficult, if not impossible, to instill in any AI system.
Until AI can learn to generalize from new information, it will remain fundamentally less intelligent than humans in key ways. It doesn’t matter how much training data you give it, when the goal is to solve problems that aren’t in the training data.
Arguments Against There Being a Ceiling
An 18-month delay is not unusual in AI history.
The period from 2022-23 was something like a cocaine high for tech bros. People got so astounded by the dizzying array of new products and models being released every few months that they came to expect that speed of progress would continue indefinitely. Now that the high has worn off, the withdrawal has begun. Investors, technologists, and short-attention-span-havers of all types have begun grumbling about how slow everything is moving now. So much of the skeptics’ complaining seems to have a subtext of, “AI has not fundamentally transformed in the last 18 months. Therefore, it will never fundamentally transform.”
I beseech you; have some patience! It took nearly 3 years between the release of GPT-3 (May 2020) and the release of GPT-4 (March 2023), so it makes perfect sense that the next level upgrade will take a similar amount of time.
Bottlenecks do not necessarily compound.
AI developers are resilient. Even if their labs stall on one component, they can still make great strides by improving other components.
Let’s say that we’ve reached the limit of compute efficiency — i.e., the number of components per microchip. We can still increase our overall compute by producing a ton more microchips! And indeed, that’s what a lot of companies are doing, spending hundreds of billions of dollars on new data centers. And even if that were impossible for some reason, and we were stuck at our current levels of compute, then we could still make progress by using our compute more efficiently with better algorithms.
Or, let’s say that we’ve reached the limit of data collection (a possibility that I find unlikely for reasons I’ll discuss below). We could still make progress if we find a way to do more with the data we currently have.
In other words, you should imagine AI progress like an 8-legged table. Even if you kick one or multiple of the legs off, the table will still be able to stand. We would need severe bottlenecks in at least three areas before progress comes to a halt.
Synthetic data looks promising.
As stated above, AI developers have essentially scraped the entire web for content. This makes it very hard to find new sources of natural data, which is a real hurdle if your development model relies on ever-increasing scale. But consider the possibility that natural data isn’t the only data we have; there is also synthetic data.
Synthetic data refers to data that is artificially generated in whole or in part in order to train other AI models. You may be skeptical that this can work; I was when I first heard about it. After all, any artificial data will have some flaws, and if you use that artificial data for training, then those flaws will compound within the model itself — a process that some developers have dubbed artificial inbreeding or Habsburg AI. Yet, despite the odds, synthetic data use has proved effective, at least in certain instances.
I’ll start with partially synthetic data — that is, data which is partly natural and partly artificial. For instance, AI developers have taken sound files (natural data) and used an automated speech-to-text program to convert those sounds into written language. That text can then be fed into an LLM, which will use it to better approximate how speech functions in real life. A similar process is taking place with YouTube videos. One AI model watches a YouTube video and describe, in words, what is happening on screen each minute; a second model keeps track of the subtitles each minute; and a third model takes that text and feed it into a larger LLM. As a result, a previously unusable source of natural data has become usable via synthetic methods.
Even fully synthetic data has shown some potential. For example, IBM Watson’s AI Lab compared a model trained on synthetic videos with one trained on real videos of humans. The researchers found that the synthetically-trained model was actually better at recognizing and describing human motions than the naturally-trained model.
So, while it may now be harder to find useful data, it is still very possible. If we can adopt partially or fully synthetic data generation, then we will still have plenty of material to work with.
AI does not have to function like human intelligence for it to be functional.
A fork is obviously different from a pair of chopsticks. They have different designs, different histories, and you hold them differently. Yet, if you are eating a bowl of noodles, it ultimately does not matter which utensil you use. Either one will suffice at the task of bringing the noodles to your mouth.
Similarly, there are significant differences in how an AI system “thinks”, versus how a human being thinks. Does this really matter? I would argue it doesn’t. As long as AI can perform human functions better than we can, the method by which it performs those functions is ultimately unimportant. Maybe humans will remain better than AI at certain particular tasks (like solving pixel puzzles), but in the big picture, on the functions that really matter, AI will still blow us out of the water.
Short-term economic developments should not be confused with long-term technological developments.
A lot of economists are warning that AI is currently a bubble — more hype and speculation than true value — which will soon pop. And you know what? I think they’re right. There is a lot of bloat in the AI sector, and a lot of AI startups that have taken investment money and produced nothing in return. AI has generated essays, pictures, and songs, but the one thing it hasn’t managed to generate yet is profit. Someday in the next few months, venture capital inflows to AI will dry up, and the techno-skeptics will smugly state their I-told-you-so’s.
But that has nothing to do with the thrust of my argument! The future of AI should not be judged by whether it can maximize shareholder value by 2025, but whether it will have a transformative impact by 2030. The “AI crash,” if such a thing occurs, will be akin to the dot-com crash of the early 2000s — a temporary setback from which the industry will recover. AI may have limited profit-making potential over the next few economic quarters, but its technical potential over the next few years remains high.
AI has exceeded expectations more often than not.
Finally, as a more general point, I want you to consider who has a greater track record when it comes to AI: the skeptics of progress, or the believers? I think that much more often than not, the skeptics have been wrong. Consider how many people prior to 2022 thought that AI would never be able to recreate human writing styles, make art on par with human art, or understand the motions of real-world objects. Consider how until recently, the market severely underpriced microchip manufacturers like Nvidia. Consider how many people dismissed the entire concept of AI as some kind of science-fiction speculation, only for AI to become the fastest-growing global industry within just a few years.
In all fairness, the skeptics haven’t been completely wrong so far. I’m sure you can cherry-pick examples of techno-optimists who have jumped the gun, or who have made utopian promises about AI that did not come true. But when looking at the broad scope of things, those who have predicted continuing exponential progress have made out much better than those who have predicted stagnation.
Conclusion
After reviewing the key points on both sides, I believe that both scenarios are plausible. However, in my estimation, it is much more likely that we have not hit a ceiling. The multiple potential avenues of progress, the possibilities of synthetic data, and the relatively short time span since the last model release all suggest that AI development is continuing apace. More specifically, I believe that the current LLM-with-RLHF approach will hold up for at least another integer-level model upgrade. I estimate with 90% confidence that we will see a GPT-5-level model released sometime in the next 2 years.
This would have huge consequences in and of itself, given how much GPT-5 would likely be able to do. With such technology, we would start to see widespread automation as AI systems perform most areas of cognitive labor far better than humans. And if we can reach further than GPT-5, which I also think is likely, then the consequences will be even harder to imagine.
Even if you are more skeptical and you think that we will not exceed GPT-4-level models anytime soon, there is still reason to brace for a major AI impact. Economists say that it can take years for a new technology to be fully integrated into the economy. Just think of how long it took between the creation of the internet (1983) and when most Americans started regularly using the internet (~2000s). Even without a fundamental increase in AI capabilities, the coming years will still see a much greater cultural and economic impact from AI as we find new ways to implement and commodify the models we currently have.
It is unlikely that AI progress has reached its peak or will do so anytime soon. But even if AI has technically hit a ceiling, the impacts of AI will still be through the roof.
Technically GPT-4, like most advanced models nowadays, is actually a multi-modal model. Meaning, it synthesizes not just text, but also other forms of content like images and videos. But since LLM is still the most commonly used term, I’ll stick with that.
As far as we know.
I think that the 'Stochastic Parrot' take is a misunderstanding of how AI works. LLMs don't actually directly store text that they then collage back together. They store concepts and the relationships between concepts. LLMs are incredibly inefficient at learning language compared to a human, but the learning process and the skills produced are very similar. This includes LLMs ability to work out of distribution on original problems, see Microsoft's "Sparks of AGI" paper for an example
"The “AI crash,” if such a thing occurs, will be akin to the dot-com crash of the early 2000s — a temporary setback from which the industry will recover. AI may have limited profit-making potential over the next few economic quarters, but its technical potential over the next few years remains high."
So much this. We love to mock pets.com while ordering dog food on chewy.com